搜狗已为您找到约906条相关结果
新浪财经知识图谱解译平台_知乎

1 新浪财经知识图谱解译平台经济就是人们生产、流通、分配、消费一切物质精神资料的总称.经济的发展与人民生活息息相关.新浪财经是国内第一大财经网...
用py爬取业绩预告pdf并识别净利润变动幅度_知乎
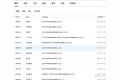
4 先下载pdf在文件都本地保存以后再 逐一识别 可以得到类似表格
Python 爬虫如何带你一键爬取王者荣耀英雄皮肤壁纸?_知乎
3个回答 - 2人关注 - 784次浏览
1 前言抓取的重点是找到每个英雄对应的id编号分析第一步先观察单个英雄的单... 每张皮肤的url分别是 第一张: https://game.gtimg.cn/images/yxzj/img201606/...更多
爬虫学习第一天 国家药品监督管理局爬取数据_知乎
6 1 基础一般分为四个步骤,注意response为text或者json2 UA伪装3 Post请求4 豆瓣电影信息爬取5 城市肯德基地址抓取需要手动发送城市,故采用post查询,...
利用python爬取小说不再书荒(request,lxml,re)_知乎
首先,导入需要使用的库:后面两个是我自己写的,文章后面会补充.定义一个获取网页源代码的方法:保存爬取到页面的全部内容(包括章节名,内容):...
Python爬虫 - 爬取肯德基餐厅信息_知乎
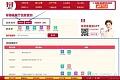
5 背景介绍这是我们要爬取的页面我们先 根据城市查询 餐厅信息选择城市后,可以看到下面的查询结果页面分析发现查询前后URL没有发生变化,显然下面的...
2022年特货产品独立站的问题大全! 你想要的都在这..._知乎

特货独立站常见的8个问题1.域名要用什么后缀的域名比较好啊?.com的最广泛,其次是用cn域名,或者是ru,co,net等等域名都可以..com是使用最为广泛的...
Python爬虫-肯德基餐厅位置信息爬取_知乎
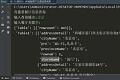
2 代码执行结果:1、输入查询城市:北京 ,此时获取的是整个北京的餐厅信息.2、输入查询城市:北京,输入餐厅关键字:前门,此时获取的是北京市以前...
python 爬虫_知乎
1 cookies and headers2.file_parames3.cert_parames4.proxy_parames5. time_out6.auth mthod7.Request,Session,Prepared_Request对象
